統計の基礎知識
算術平均(相加平均) $$\overline x = \frac{x_1 + x_2 + … + x_n}{n} = \frac{\sum\limits^n _{i = 1} x_i}{n}$$
加重平均 $$\overline {x_W} = \frac{W_1x_1 + … + W_n x_n}{W_1 + … + W_n} W_i : 重み$$
幾何平均(相乗平均) $$m_g = \root n \of {\prod\limits^n _{i = 1} x_i }$$
分散 $$s^2 = \frac{\sum\limits^n _{i = 1} {(x_i - \overline x)^2}}{n}$$
標準偏差 $$s = \sqrt{\frac{\sum\limits^n _{i = 1} {(x_i - \overline x)^2}}{n}}$$
変動係数 $$c.v. = \frac{s}{\overline x}$$
最頻値(モード)
中央値(メジアン)
相関係数 $$r = \frac{\sum\limits^n _{i = 1} {(x_i - \overline x)^2 (y_i - \overline y)^2 }}{\sqrt{\sum\limits^n _{i = 1} {(x_i - \overline x)^2}}\sqrt{\sum\limits^n _{i = 1} {(y_i - \overline y)^2}}}$$ r>0:正の相関関係、r<0:負の相関関係
確率分布:統計量に対して想定されるさまざまな分布の総量
確率変数:理論的に確率で決まっている変数
生起確率:確率変数がとるそれぞれの値に対して起こりやすさ。合計は100%
$$ 確率分布\left\{ \begin{array}{l} 離散型\left\{ \begin{array}{l}一応分布:すべての確率変数のとる生起確率が一定の事象に関する分布\\ 二項分布:n回のベルヌーイ試行における成功回数の分布\\ ポアソン分布:試行回数が大きい中でまれにしか起こらない事象の生起回数の分布 \end{array} \right. \\ 連続型\left\{ \begin{array}{l} 正規分布:試行回数が大きい時の二項分布の近似分布\\ Z分布:標準化した統計量の分布。平均は0、分散は1、標準正規分布\\ t分布:母分散の代わりに不偏分散をつかったt値の分布\\ \chi ^2 分布:Z値をデータの数だけ平方和した分布\\ F分布:二つの母集団からとってきた\chi ^2もしくは不偏分散の比であるF値の分布\end{array} \right. \end{array} \right. $$正規分布
左右対称で平均値付近に集積するようなデータの分布を表した連続的な変数に関する確率分布
正規分布の確率密度関数 $$f(x) = \frac{1}{\root \of {2 \pi \sigma^2}} e^{- \frac{(x- \mu)^2}{2 \sigma^2}}$$ $$\mu = 0,\sigma^2 = 1の時の標準正規分布$$ $$f(x) = \frac{1}{\root \of {2 \pi }} e^{- \frac{x^2}{2 }}$$
ポアソン分布
所与の時間間隔で発生する離散的な事象を数える特定の確率変数xを持つ離散確率分布。単位時間当たりの生起確率 $$確率質量関数f(x) = \frac{e^{-\lambda} \lambda^x}{x!}$$ $$\lambda:所与の単位時間区間内で発生する事象の期待発生回数。試行回数n ×生起確率p$$ $$x:事象が所与の単位時間区間内に起こる回数$$
指数分布
事象の生起間隔(ある事象が起こって次にまた発生するまでの間隔。) $$f(x) = \lambda e^{-\lambda t}$$
χ2分布
標準化変量Zを二乗和したχ2値が従う確率分布で母分散の信頼区間の推定やクロス集計の検定に用いる。 $$\chi^2(n) = \frac{\sum\limits^n _{i = 1} {(x_i - \mu)^2}}{\sigma^2}$$$$ n:自由度、データの数$$
マルコフ過程
マルコフ性をもつ確率過程。未来の挙動が現在の値だけで決定され、過去の挙動と無関係
度数分布表
統計資料を階級に分け各階級ごとの度数を表の形式で表したもの
$$ データ\left\{ \begin{array}{l} カテゴリー型(質的データ)\left\{ \begin{array}{l}名義型\\ 順序型 \end{array} \right. \\ 数値型(量的データ)\left\{ \begin{array}{l} 離散型\\ 連続型\end{array} \right. \end{array} \right. $$ [9,2,9,6,10,5,2,9,6,2,1,3,7,7,9,1,9,4,5,5]最小と最大値を探す
最大値と最小値の範囲をいくつか(階級数)に分ける。各区分の幅を階数幅
度数の欄にその回数に属するデータの個数を数えて記入
相対度数の欄には度数をパーセントで表す
累積度数の欄はその階級までの度数の合計を書く
累積相対度数の欄は累積度数欄の数値をパーセントで表す
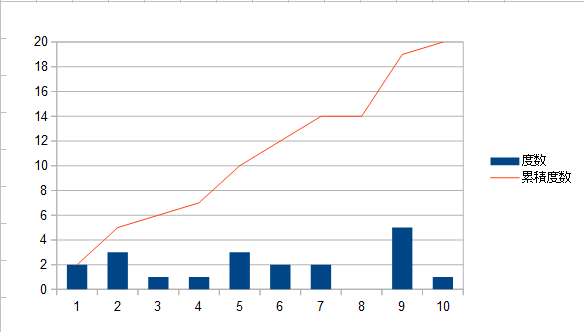
| 階数 | 度数 | 相対度数 | 累積度数 | 累積相対度数 |
|---|---|---|---|---|
| 1 | 2 | 10 | 2 | 10 |
| 2 | 3 | 15 | 5 | 25 |
| 3 | 1 | 5 | 6 | 30 |
| 4 | 1 | 5 | 7 | 35 |
| 5 | 3 | 15 | 10 | 50 |
| 6 | 2 | 10 | 12 | 60 |
| 7 | 2 | 10 | 14 | 70 |
| 8 | 0 | 0 | 14 | 70 |
| 9 | 5 | 25 | 19 | 95 |
| 10 | 1 | 5 | 20 | 100 |